Building AI Apps with LaunchDarkly and LangChain
Read time: 14 minutes
Last edited: Sep 18, 2024
Overview
This guide explains using LaunchDarkly feature flags with the LangChain Python package to build artificial intelligence (AI) applications with large language models (LLMs).
Prerequisites
LangChain is a framework for developing AI applications powered by LLMs. It provides modular components for developing AI applications. If you are new to LangChain, we recommend reading the LangChain Quickstart.
Use feature flags to control AI applications
Innovation in AI applications is rapid. Organizations that use AI iterate through many different AI models spanning multiple modalities, including text, image, and audio. Quickly choosing between models and configurations is critical to the success of AI applications, and measurement and experimentation is necessary to make those choices well.
As a feature management and experimentation platform, LaunchDarkly can help organizations manage AI apps in the following ways:
- Enabling or disabling new models: LaunchDarkly feature flags decouple deployment from release so that you can release models on your terms. You can use feature flags as a kill switch to disable models if they produce unexpected results.
- Iterate, optimize, and release prompts: you can use feature flags to customize and experiment with your prompts.
- Target groups: you can use feature flags to enable specific models or configurations for different contexts or groups of contexts. For example, you can implement token limits and model usage based on the customer's account type to control your costs and tailor the end-user experience.
- Measure effectiveness: you can use LaunchDarkly to run experiments to measure the effectiveness of different models and configurations in production.
This guide shows you how to use LaunchDarkly feature flags to control AI applications built with LangChain for Python. While this is only one specific framework, many of the patterns described here apply to using LaunchDarkly feature flags more generally when building AI applications.
Install LangChain
To install LangChain, run:
pip install langchain
You can read more about the LangChain installation process in the LangChain docs.
To install the additional packages used in this guide, run the following:
pip install boto3 openai replicate
Write a LangChain chain
Modern AI applications often consist of more than a single API call to a foundation language model. They can require retrieving data to provide context for the prompt and post-processing the output before returning it to the user. More complex applications may include multiple language model calls, each dependent on the output of other language models. AI apps may also include calls to agents that execute actions. Because an AI application consists of multiple steps, LangChain represents them as pipelines, which it calls chains.
We'll start with a simple LLM chain: a prompt and an LLM model that will use that prompt.
We are going to use an LLM to answer user questions, so we will use this prompt:
You are a helpful assistant. Please answer the user's question in aconcise and easy to understand manner.Here is a question: INSERT USERS QUESTION HERE
We will use one of the models provided by Amazon Bedrock for the LLM model. Amazon Bedrock provides multiple foundation models, including those from AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, through a single API, allowing us to switch between models easily. We use Anthropic's Claude v2 model, their most powerful model at the time of writing (November 2023).
Here is an example:
from langchain.llms import Bedrockfrom langchain.prompts import PromptTemplatefrom langchain.schema.output_parser import StrOutputParserhelpful_prompt_template = PromptTemplate.from_template("""\You are a helpful assistant. Please answer the user's question in a conciseand easy to understand manner.Here is a question: {question}""")llm = Bedrock(model_id="anthropic.claude-v2",model_args={"max_tokens_to_sample": 300})output_parser = StrOutputParser()helpful_chain = helpful_prompt_template | llm | output_parser
In the code above, LangChain composes the prompt, language model, and output parser into a chain using the pipe operator |. This syntax is called LangChain Expression Language (LCEL). The LCEL is a declarative specification of AI chains. LangChain calls these atomic components of a chain runnables. You can read more about the LCEL in the LangChain Docs or the blog post introducing the syntax.
In addition to the prompt and model, our chain includes an output parser, StrOutputParser. An output parser post-processes the outputs of the language model. Chains can use output parsers for several tasks, including parsing structured formats like JSON, content moderation, and formatting the output for display. The one used in this chain, StrOutputParser, returns the output of the language model as a string and serves as a placeholder in these examples.
We run the chain using its invoke method. We provide the input of the prompt as a question, containing the user's question.
To stay on brand, we ask the model how to use feature management to deploy software safely:
question = "How can you use feature management to safely and quickly deploy software?"answer = helpful_chain.invoke({"question": question})print(answer)
Here is a concise answer to how feature management can help safely and quickly deploysoftware:Feature management allows you to deploy code changes incrementally by enabling ordisabling features without redeploying the entire application. This makes it easier toroll out changes safely. You can target new features to certain users or groups firstto test them before rolling them out more broadly. If any issues arise, you can simplydisable the problematic feature. This makes it faster and lower risk to deploy incrementalupdates. Overall, feature management gives more control over releasing changes andhelps accelerate development cycles while maintaining quality.
After you have a working chain, you can deploy it to production. You can read more about deploying LangChain chains in the LangChain documentation.
We will also consider a more whimsical prompt. ELIZA was an early example of a chatbot. It conversed with the user as a therapist who responded to questions by asking the user additional questions. The original ELIZA program consists of many hand-crafted rules and heuristics to parse the user's question and produce output.
Today, we can replicate ELIZA's behavior through prompt instructions to an LLM:
eliza_prompt_template = PromptTemplate.from_template("""\You are a Rogerian therapist. Please answer the user's question with a questionon the same topic. If you don't understand the user's question, please ask themto tell you more.Here is a question: {question}""")chain = eliza_prompt_template | llm | output_parserchain.invoke({"question": question})
Could you tell me more about why you're interested in using feature management to safely andquickly deploy software? What problems are you hoping feature management will help solve?
Comparing the two chains we have written, we see that they only differ in the prompt step. Instead of having two chains, we will see how to write a single chain with a configurable prompt and use a LaunchDarkly feature flag to select which prompt to use. A single configurable chain controlled by a feature flag will allow us to change the prompt served in production and experiment or target users with different prompts.
Set up the LaunchDarkly SDK
We'll use the LaunchDarkly Python SDK. Instructions on how to get started with the LaunchDarkly Python SDK are covered in the Python SDK Reference.
First, install the LaunchDarkly Python SDK by running:
pip install launchdarkly-server-sdk
The Python SDK uses an SDK key. Keys are specific to each project and environment. They are available from the Environments list for each project. To learn more about key types, read Keys.
We import the LaunchDarkly client, configure it with your SDK key, and then initialize it:
import ldclientfrom ldclient.config import Configldclient.set_config(Config("sdk-key-123abc"))client = ldclient.get()
Select a prompt with a feature flag
We customize the prompt using LangChain's runtime configuration API, described in their configure docs. The configurable_alternatives method on the helpful_prompt_template lets us list multiple alternatives for the runnable. We need to provide a key and a runnable for each alternative. In our case, the helpful_prompt_template is the default, with a key of "helpful", and the eliza_prompt_template is the only alternative, with a key of "eliza".
from langchain.schema.runnable import ConfigurableFieldprompt = helpful_prompt_template.configurable_alternatives(ConfigurableField(id="prompt"),default_key="helpful",eliza=eliza_prompt_template)chain = prompt | llm | output_parser
We can then select which prompt to use by setting the prompt field in the chain's configuration.
To use the ELIZA prompt in the chain, we run:
(chain.with_config(configurable={"prompt": "eliza"}).invoke({"question": question}))
Now that we can configure the prompt, we want to be able to control that configuration. So, we create a LaunchDarkly feature flag to provide the value of prompt to the chain configuration. We can then use rules on that flag to target particular contexts or to run an experiment.
To learn more, read Creating new flags.
For this example, we create a feature flag named langchain-prompts with two variations that have the same values as the keys in the chain configuration: "helpful" and "eliza".

We use the client variation method and a context to evaluate the feature flag. To learn more about how flags are evaluated, read Evaluating flags and Flag evaluation reasons. For more information about how contexts are specified, read Context configuration.
Here's how to use the variation method:
from ldclient import Contextcontext = Context.builder("context-key-123abc").name("Sandy").build()prompt_variation = client.variation("langchain-prompts", context, "helpful")(chain.with_config(configurable={"prompt": prompt_variation}).invoke({"question": question}))
Here is a concise answer to how feature management can help safely and quicklydeploy software:Feature management allows you to deploy new or updated features to selectusers or groups first, before rolling them out more broadly. This lets you testfeatures with real users and get feedback, without impacting your whole userbase. If issues arise, you can disable the feature or roll it back, reducingrisk. Feature flags let you control feature releases remotely, enabling rapiditeration. Overall, feature management enables incremental delivery andtesting of changes, allowing faster and safer software deployment.
Toggle on the flag to serve the "eliza" variation:

After we turn on the flag in LaunchDarkly, we can invoke the chain with the same question. Now, the ELIZA prompt is used instead of the helpful prompt and the response is a question.
(chain.with_config(configurable={"prompt": prompt_variation}).invoke({"question": question}))
Could you tell me more about why you are interested in using feature management for software deployment? I'd like to better understand your goals and context before suggesting how feature management could help.
We can use the langchain_prompts feature flag as a kill switch. If we find the ELIZA prompt to have problems we can immediately turn targeting off to revert to using the helpful prompt:

Instead of deploying the ELIZA variation to everyone, we can use targeting rules to target specific users, segments, or contexts based on their attributes. For example, we can serve the ELIZA prompt to users with an email address in the example.com domain and the helpful prompt for everyone else. In the example below, the ELIZA prompt will be used for the user context-key-456def because their email is in the example.com domain.
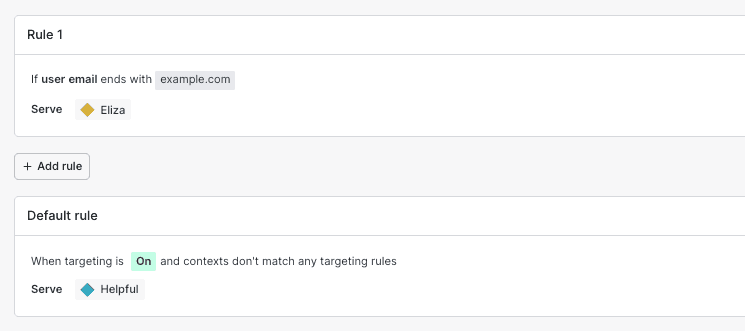
Here's how to configure this in Python:
You can read more about targeting in Target with flags.
Before launching the ELIZA chain, we should run an experiment on it. We can use LaunchDarkly's Experimentation feature to run an experiment on the ELIZA prompt to measure its effectiveness.
You can read more about LaunchDarkly's Experimentation feature in Experimentation.
Here is an example experiment design for an ELIZA prompt experiment:
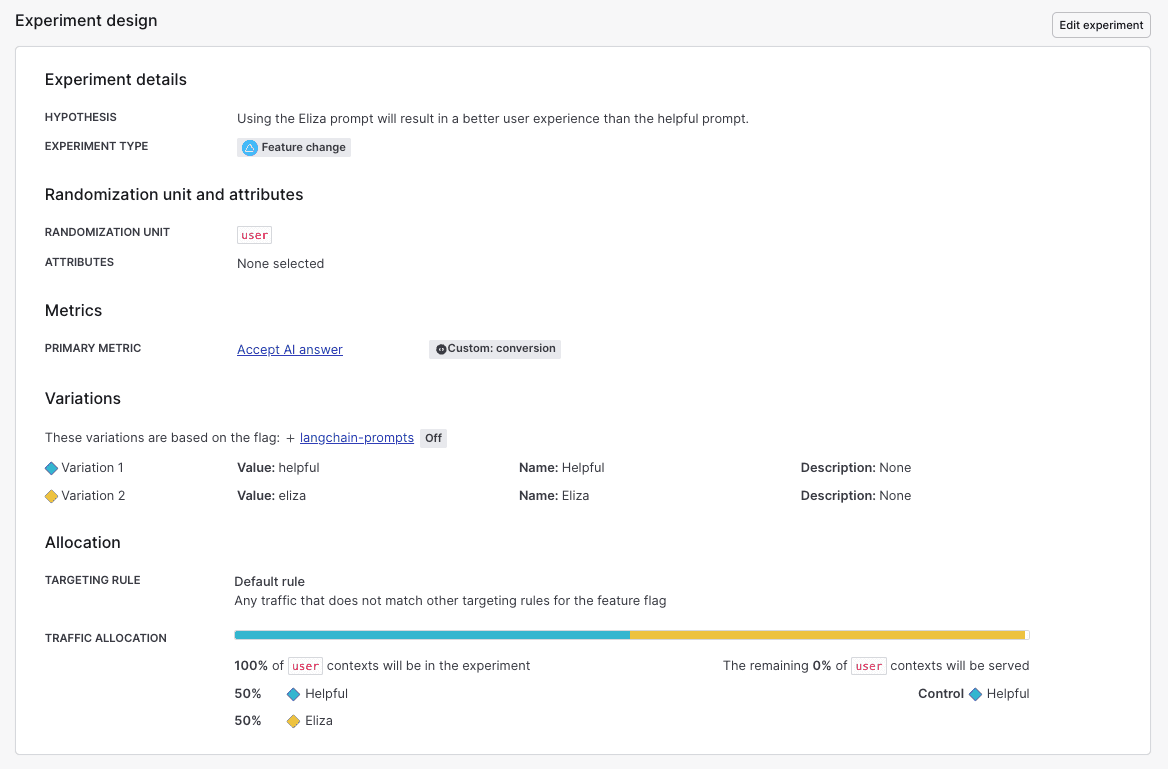
We will not cover the details of experimenting on LLMs in this guide. You can read about best practices for running experiments on LLMs in this Microsoft Experimentation Platform article How to Evaluate LLMs: A Complete Metric Framework.
Update prompts with feature flags
There are several ways that we can update prompts using feature flags. We can add new prompt alternatives to the variations, store prompts in feature flag variations, or store prompt template variables in feature flags.
Add a new variation to a feature flag
Suppose that we want to try another prompt variation for our app. Adding a new prompt requires adding an alternative in the chain configuration and a new variation to the feature flag that references that alternative.
As an example of an alternative prompt, we consider prompt that replies as an expert. First, we define a new prompt template and add it to the alternatives list of the prompt runnable with the name expert.
from langchain.schema.runnable import ConfigurableFieldexpert_prompt_template = PromptTemplate.from_template("""\You are an expert assistant. Reply to the the user's question with a detailed and technical answer.Here is a question: {question}""")prompt = helpful_prompt_template.configurable_alternatives(ConfigurableField(id="prompt"),default_key="helpful",eliza=eliza_prompt_template,# --- New alternativeexpert=expert_prompt_template# ---)chain = prompt | llm | output_parser
Then add a new variation to the langchain-prompts feature flag with the value expert:
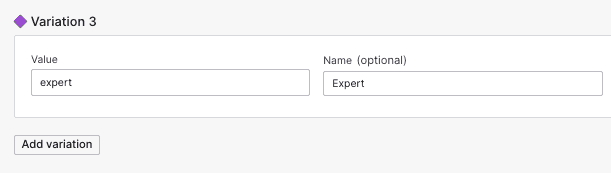
Once we have deployed the code with the expert alternative, we can start serving the expert prompt in an experiment or turning it on with a targeting rule.
Store prompts in feature flags variations
Specifying a prompt instance for each variation means that although we can dynamically change which prompt is served at runtime, adding a new prompt requires a code deployment. A more flexible alternative is to set the variation values of the feature flag to the prompt template itself.
We create a feature flag named langchain-prompt-templates with the following JSON variations:
{"template": "You are a helpful assistant. Please answer the user's question in a concise and easy to understand manner.\n\nHere is a question: {question}"}{"template": "You are a Rogerian therapist. Please answer the user's question with a question on the same topic. If you don't understand the user's question, please ask them to tell you more.\n\nHere is a question: {question}"}
Instead of specifying labels like helpful and eliza, we put the prompt template into the variation value. We use a JSON string because LaunchDarkly string variation values do not support newlines.
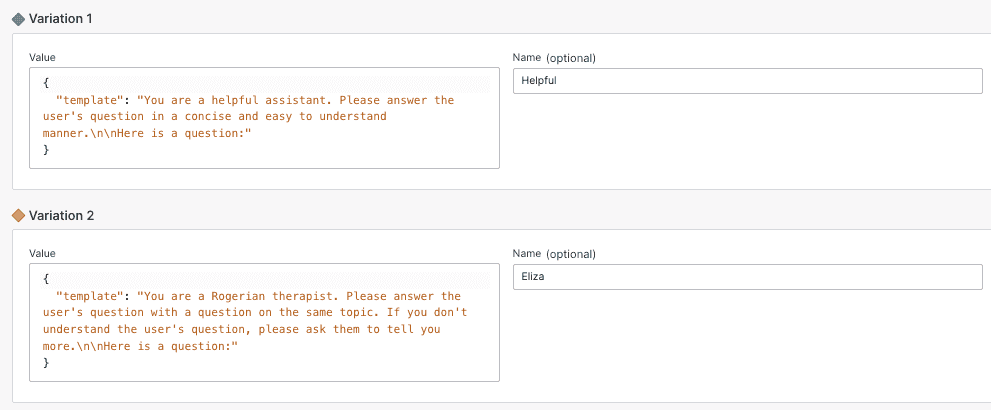
To override the template text used by the prompt, we use the configurable_fields method, which configures specific fields of a runnable. We use the helpful_prompt_template as the default and then override the template field, which contains the template's text, with the feature flag's variation value:
from ld_langchain.runnables import LDRunnableprompt = helpful_prompt_template.configurable_fields(template=ConfigurableField(id="prompt_template",))chain = prompt | llm | output_parservariation = client.get("langchain-prompt-templates", context, prompt.default.template)(chain.with_config(configurable={"prompt_template": variation.get("template")})..invoke({"question": question}))
An advantage of putting the prompt in the variation value is that we can add a new prompt template without updating our code. For example, we could add the expert prompt template by defining a new variation with the following value:
{"template": "You are an expert assistant. Reply to the the user's question with a detailed and technical answer.\n\nHere is a question: {question}"}
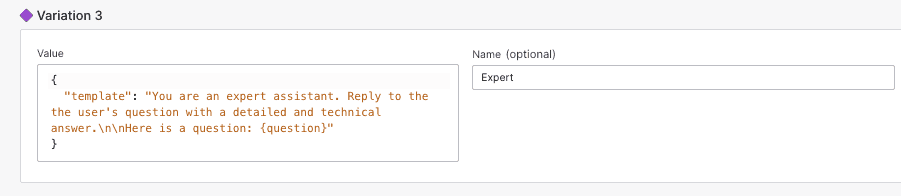
Store prompt template variables in feature flags
In the examples above, the prompts have a similar structure. So, instead of storing the entire prompt string in the variation, we could only store template variables that customize a prompt.
For example, we could use the following prompt template:
prompt = PromptTemplate.from_template("""\You are an {adjective} assistant. Answer the user's question {instruction}. Question: {question}""")chain = prompt | llm | output_parser
In addition to the question template variable, this prompt template requires an adjective and instruction template variables. We customize the prompt at runtime through the values provided to these template variables. The chain now expects the input dict to contain adjective and instruction keys.
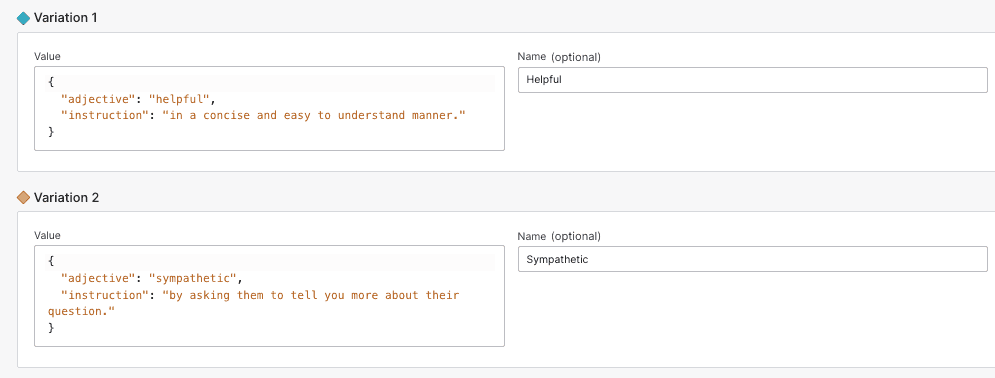
We create a feature flag langchain-template-variables feature flags with the following JSON variations, which contain the values of adjective and instruction needed by the prompt template:
{"adjective": "helpful", "instruction": "in a concise and easy to understand manner."}{"adjective": "sympathetic", "instruction": "by asking them to tell you more about their question."}
Here's how we run this:
variation = client.get("langchain-prompt-inputs", context,{"adjective": "helpful", "instruction": "in a concise and easy to understand manner."})chain.invoke({"question": question, **variation})
Select and configure LLMs
All of our examples so far have focused on customizing prompts. However, we can customize any component in a chain. This section will provide examples of how to customize the LLM model used in the chain.
In addition to the Claude model we have been using thus far, we want to consider another model on Bedrock, an OpenAI model, and a Llama model served by Replicate.
In this example, we consider some chat models among the alternatives, so the prompt format is slightly different than the ones previously used:
from langchain.llms.openai import OpenAIfrom langchain.llms.replicate import Replicatefrom langchain.prompts import ChatPromptTemplatefrom langchain.schema import SystemMessagellm = Bedrock(model_id="anthropic.claude-instant-v1").configurable_alternatives(ConfigurableField(id="model"),default_key="claude",titan=Bedrock(model_id="anthropic.titan-instant-v1"),openai=OpenAI(temperature=0, model="gpt-3.5-turbo"),replicate=Replicate(model="meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d"))chat_prompt_template = ChatPromptTemplate.from_messages([SystemMessage(content="You are a helpful assistant. Please answer the user's question in a concise and easy to understand manner."),("human", "{question}")])chat_chain = chat_prompt_template | llm | output_parser
We then create a feature flag named langchain-llm-models with a variation for each of the alternatives: "claude", "titan", "openai", and "replicate":
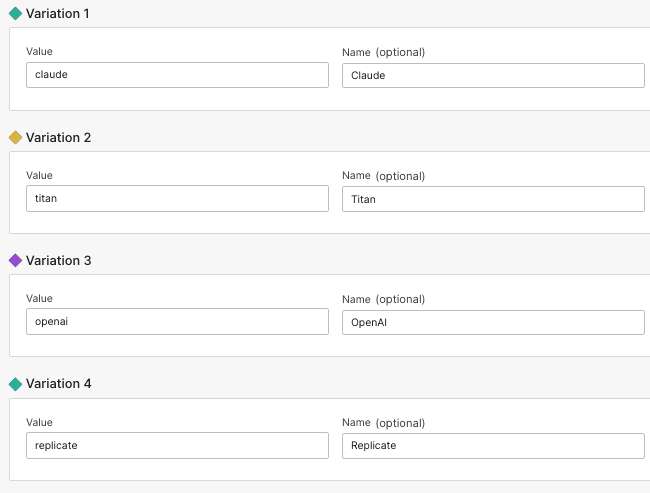
When running the chain, we use the alternative provided by the variation of langchain-llm-models:
variation = chain.get("langchain-llm-models", context, "claude")(chat_chain.with_config(configurable={"model": variation}).invoke({"question": question}))
Instead of choosing among different models, we can configure the parameters of a model. For example, we can configure both the model_ids and the temperature with the' Bedrock' class:
llm = Bedrock(model_id="anthropic.claude-v2").configurable_fields(model_id=ConfigurableField(id="model_id"),model_args=ConfigurableField(id="model_args"))chain = helpful_prompt_template | llm | output_parser
Now that we have made the temperature field configurable, we create a feature flag named langchain-llm-model-args with JSON variations containing possible values for the model_id and model_kwargs fields:
{"model_id": "anthropic.claude-v2"}{"model_id": "anthropic.claude-v2", "model_kwargs": {"temperature": 1}}{"model_id": "anthropic.claude-instant-v1", "model_kwargs": {"temperature": 0}}
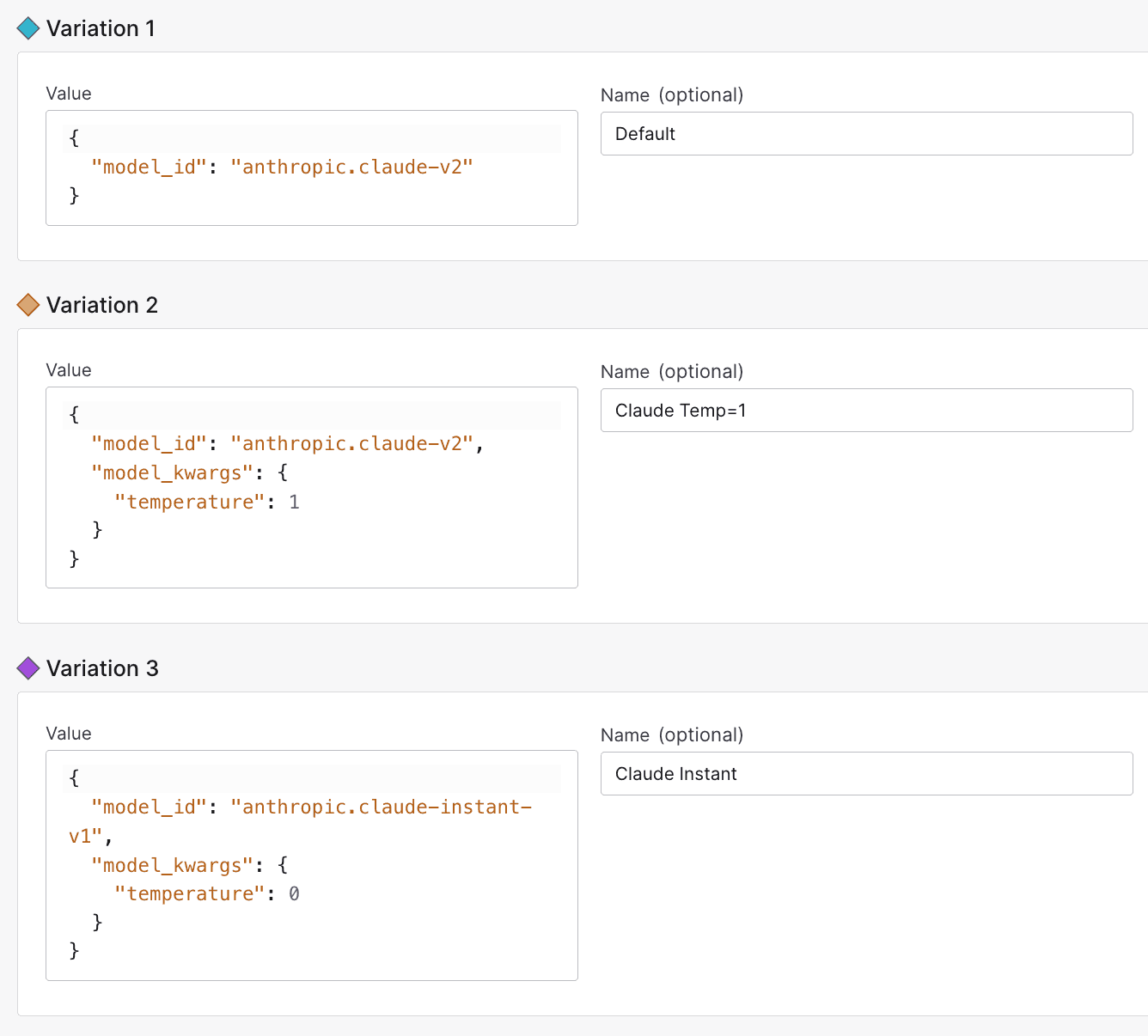
variation = chain.get("langchain-llm-model-args", context,{"model_id": "anthropic.claude-v2", "model_kwargs": {"temperature": 0.5}})(chat_chain.with_config(configurable={**variation}).invoke({"question": question}))
Conclusion
In this guide, you learned how to use LaunchDarkly feature flags with the LangChain Python package to build AI applications with LLMs. LLMs are rapidly evolving, and we expect that there will soon be many more ways to use LaunchDarkly with LangChain.
Your 14-day trial begins as soon as you sign up. Get started in minutes using the in-app Quickstart. You'll discover how easy it is to release, monitor, and optimize your software.
Want to try it out? Start a trial.