Experiment size and run time
Read time: 3 minutes
Last edited: Dec 10, 2024
Overview
This topic explains how to decide on the number of contexts to include and the run time for an experiment.
Choosing your sample size
The number of contexts included in an experiment is called the sample size. The larger the sample size for an experiment, the more confident you can be in its outcome. How big your sample size should be depends on how confident you want to be in the outcome and how large the credible intervals are for your metrics.
You can also use LaunchDarkly's sample size calculator to estimate the minimum detectable effect and sample size and duration for your experiments. To learn more, read Choose a sample size.
Total original exposures
The total original exposures graph and table displays how many unique contexts have encountered each variation within the experiment over time:
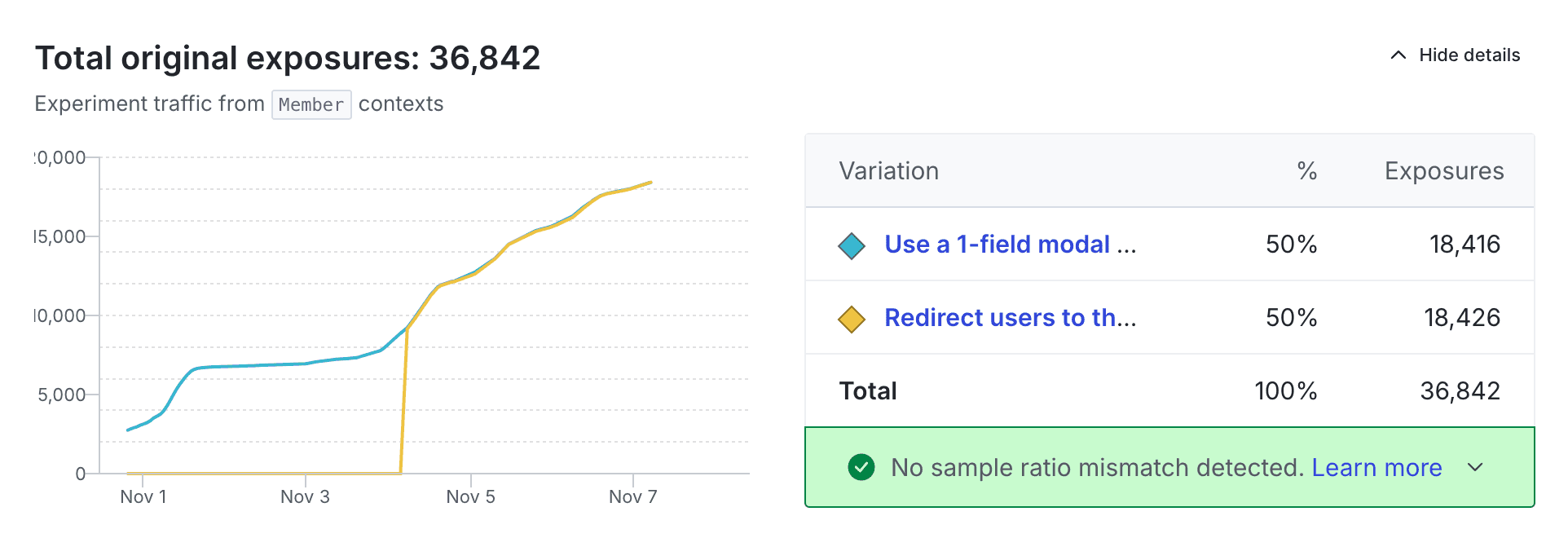
Here's how the table counts unique contexts:
- The table only counts contexts with the same context kind as the experiment's randomization unit. For example, if your experiment's randomization unit is
user, then the table counts onlyusercontexts. The table won't include anydeviceororganizationcontexts that are in the experiment. To learn more, read Randomization units. - If the same context is in the experiment multiple times, the table counts the context only once.
Sample size estimator
After you begin running an experiment, the experiment's Results tab displays a sample size estimator that gives an estimate of how much more traffic needs to encounter your experiment before reaching your chosen probability to be best or desired p-value. Experiments with more than two variations do not display a sample size estimator.
In this example, for a 90% probability of being best, 53,285 more request contexts should be in the experiment before you stop the iteration and roll out the winning variation to all contexts:

For Bayesian experiments, you can use the menu to see how many more contexts you need for a probability to be best of 80%, 90%, or 95%.
For frequentist experiments, you can use the menu to see how many more contexts you need for your chosen p-value.
To be confident that the winning variation is the best out of the variations tested, wait until the sample size estimator indicates you have reached the needed number of contexts. Alternatively, if there is a low level of risk in rolling out the winning variation early, or if you don't anticipate a significant impact on your user base, you can end the experiment before you reach that number.
Determining how long to run an experiment for
You may not always know how long to run an experiment for. To help decide, you should consider:
- The current probability of the winning variation being the best and how long it would take to improve your confidence, and
- the level of risk involved in rolling out the winning variation to all contexts.
We recommend running experiments for two to four weeks. If you’re time constrained, then run them as long as you can. In some cases, you only may be able to run an experiment for a few days, such as if your marketing campaign is only 48 hours long. It’s still valuable to run short experiments, because making decisions using some data is better than making decisions using no data.